
5 cấu trúc dữ liệu Javascripter cần biết
Trong thế giới lập trình, biết code và code được sản phẩm thôi vẫn là quá ít ỏi so với những vấn đề mà công nghệ cần giải quyết. Một lập trình viên giỏi và có nhiều kinh nghiệm không chỉ cần biết cách tạo ra sản phẩm, mà cần phải biết làm thế nào để hiệu quả làm việc và chất lượng sản phẩm ở mức cao nhất. Đó có thể là kéo giảm lượng thời gian cần bỏ ra để tạo sản phẩm hay giảm mức sử dụng bộ nhớ, nhiên liệu của phần cứng. Để làm được những điều này, một trong những kinh nghiệm cần thiết là vận dụng hợp lý các cấu trúc dữ liệu cơ bản và nâng cao, để giải quyết các vấn đề lập trình. Sự khác biệt giữa trình độ của các lập trình viên được thể hiện rất rõ thông qua việc sử dụng thành thạo cấu trúc lập trình phức tạp.
Suốt quá trình phát triển của Javascript, các lập trình viên đã vận dụng các cấu trúc dữ liệu sẵn có để tạo ra các cấu trúc phức tạp hơn nhằm giải quyết hiệu quả nhất các vấn đề khó.
Trước hết, ta cần làm rõ cấu trúc dữ liệu (Data Structure) là gì. Hiểu một cách đơn giản, data structure là tổng hợp các kỹ thuật dùng để lưu trữ, tổ chức dữ liệu và quản lý dự liên kết giữa các dữ liệu để việc truy cập, điều chỉnh diễn ra nhanh chóng và hiệu quả nhất. Như vậy, đối với từng vấn đề khác nhau, ta sẽ cần có data structure khác nhau để đảm bảo dữ liệu được quản lý, truy xuất và chỉnh sửa dễ dàng. Với cấu trúc dữ liệu phù hợp, ta có thể:
- Quản lý cơ sở dữ liệu với quy mô lớn
- Truy xuất những dữ liệu cụ thể trong cơ sở dữ liệu
- Tạo ra các thuật toán phù hợp cho từng loại chương trình khác nhau
- Xử lý số lượng lớn yêu cầu của người dùng cùng lúc
- Đơn giản hoá và đẩy nhanh tốc độ xử lý dữ liệu.
Việc nắm rõ các cấu trúc dữ liệu là cực kỳ cần thiết để có thể trở thành một coder giỏi, vì hầu hết các giải pháp tối ưu hiệu quả của các phần mềm đều liên quan mật thiết đến cấu trúc dữ liệu. Đây cũng là yêu cầu quan trọng nhất mà các nhà tuyển dụng đặt ra cho ứng viên.
Trong Javascript, ta có hai loại cấu trúc dữ liệu: Primitive Data Structure (Cấu trúc dữ liệu có sẵn) và Non-Primitive Data Structure (Cấu trúc dữ liệu có sẵn). Primitive Data Structure là những cấu trúc được cung cấp sẵn bởi ngôn ngữ và ta có thể dùng ngay. Cấu trúc này bao gồm `array`, `object`, `Boolean`, `string`, v/v. Non-Primitive Data Structure, ngược lại, là những cấu trúc không có sẵn và lập trình viên phải thực hiện một số bước thiết lập khi có thể sử dụng. Dưới đây là 5 cấu trúc dữ liệu quan trọng mà bất kì người dùng Javascript nào cũng cần phải nắm rõ.
1. Array
Array (mảng) là một trong những cấu trúc có sẵn (Primitive Data Structure), cơ bản nhất của lập trình Javascript, nó dùng để chứa dữ liệu theo dạng danh sách và có thể truy xuất để sử dụng trong tương lai. Mỗi array đều có độ dài (length) được xác định và mỗi phần tử (items) bên trong array sẽ có một số chỉ (index) để xác định vị trí của phần tử dữ liệu cần dùng. Array thường được sử dụng trong các bảng tính cơ bản, hoặc được kết hợp với các cấu trúc phức tạp hơn, như hashtable.
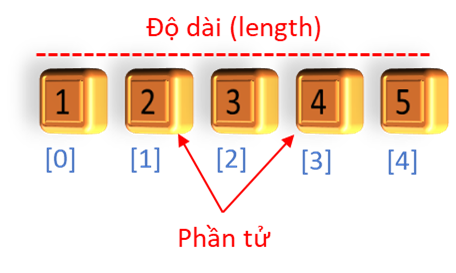
Ưu điểm:
- Dễ dạng sử dụng vì array được cung cấp sẵn bởi Javascript, và cách sử dụng đơn giản
- Có thể ứng dụng rất nhiều vấn đề khác nhau
- Là nền tảng để tạo nên các cấu trúc dữ liệu phức tạp hơn
Nhược điểm
- Thiếu hiệu quả trong việc sắp xếp dữ liệu
- Việc chèn dữ liệu, xoá dữ liệu hoặc thay đổi thứ tự dữ liệu cần nhiều tài nguyên phần cứng
2. Queues
Queues (hàng đợi) là một cấu trúc dữ liệu quan trọng, được ứng dụng rất nhiều trong lập trình, đặc biệt là lập trình Back-end. Khi số lượng yêu cầu của người dùng quá lớn, việc xử lý cùng một lúc sẽ làm tắc nghẽn máy chủ và tạo ra những vấn đề không mong muốn. Đó chính là lúc “hàng đợ” phát huy tác dụng, giúp điều hòa các tác vụ mà máy chủ cần phải xử lý.
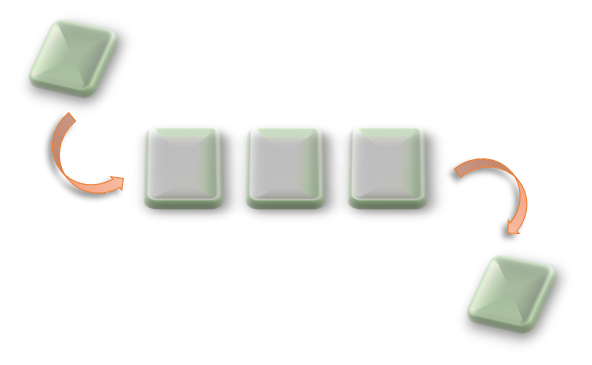
Về cơ bản, queue có cấu tạo tương tự như Array trong Javascript, tuy nhiên, thứ tự chèn và cắt dữ liệu trong hàng đợi sẽ tuân theo quy tắc FIFO (First In – First Out / Vào trước – Ra trước). Bạn hãy tưởng tượng một hàng đợi như đường hầm một chiều. Xe đi vào đầu này và đi ra vào đầu còn lại, xe nào vào trước thì sẽ ra trước, Nếu một phần tử bị tắc nghẽn bên trong hàng đợi, các phần từ khác cũng sẽ bị ảnh hưởng cho đến khi phần tử đó được “giải phóng”.
Ưu điểm:
- Các phần tử được sắp xếp theo theo thứ tự phần tử được chèn vào
- Thời gian xử lý đối với hàng đợi sẽ thấp hơn so với mảng
Nhược điểm:
- Chỉ có thể lấy ra phần tử ở cuối hàng đợi mà không thể lấy ra các phần tử khác
3. Linked List
Khac với hai cấu trúc dữ liệu ở trên, Linked List (danh sách liên kết) không sử dụng cách lưu trữ dữ liệu theo thứ tự. Thay vào đó, `linked list` sửu dụng một hệ thống liên kết thay cho thứu tự và số chỉ: mỗi một phần tử sẽ được lưu trữ trong linked list sẽ giữ một địa chỉ để trỏ đến một phần tử khác trong danh sách (địa chỉ này có thể là null – không trỏ đến phần từ nào khác). Cứ như vậy, các phần tử được liên kết với nhau thông qua các địa chỉ phần tử nắm giữ. Như vậy, khi ta biết một phần tử bất kỳ, ta có thể dễ dàng truy xuất phần tử mà nó liên kết trong qua địa chỉ của phần tử đó. Thông thường Linked List được sử dụng trong trường hợp các phần tử không cần được sắp xếp theo thứ tự và việc thêm hoặc xóa phần tử khỏi danh sách cần được thực hiện nhanh chóng.
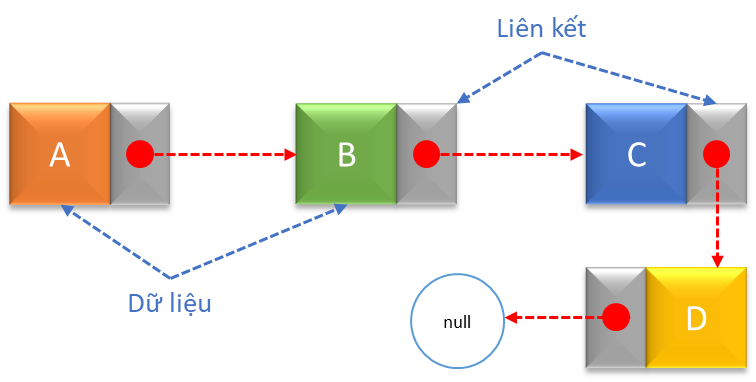
Ưu điểm:
- Dễ dạng thêm hoặc xoá phần tử trong danh sách
- Cấu trúc đơn giản hơn Array
Nhược điểm:
- Khó khăn trong việc truy ngược các phần tử, vì mỗi phần tử chỉ nắm giữ địa chỉ của phần tử liên kết
- Sử dụng nhiều bộ nhớ hơn Array
- Khó khăn trong việc truy xuất một phần tử cụ thể
4. Trees
Tương tự như Linked List, Trees (Cấu trúc nhánh) cũng sử dụng hệ thống liên kết thay cho thứ tự và số chỉ. Điểm khác biệt so với Linked List nằm ở chỗ, dữ liệu được lưu trữ bởi Trees thường là các dữ liệu được phân cấp rõ ràng. Về mặt kỹ thuật, mỗi phần tử bên trong Tree có thể liên kết với nhiều phần tử ở cấp thấp hơn.
Trong mỗi Tree, ta sẽ có một phần tử gốc (root element), từ phần tử gốc này sẽ phân cấp thành nhiều nhánh nhỏ hơn xuống dưới. Mỗi một phần tử sẽ liên kết với các phần tử ở cấp thấp hơn, được gọi là phần tử con (child nodes), và cứ thế, các phần tử tiếp tục phân nhánh để tạo ra một cấu trúc Tree hoàn chỉnh.
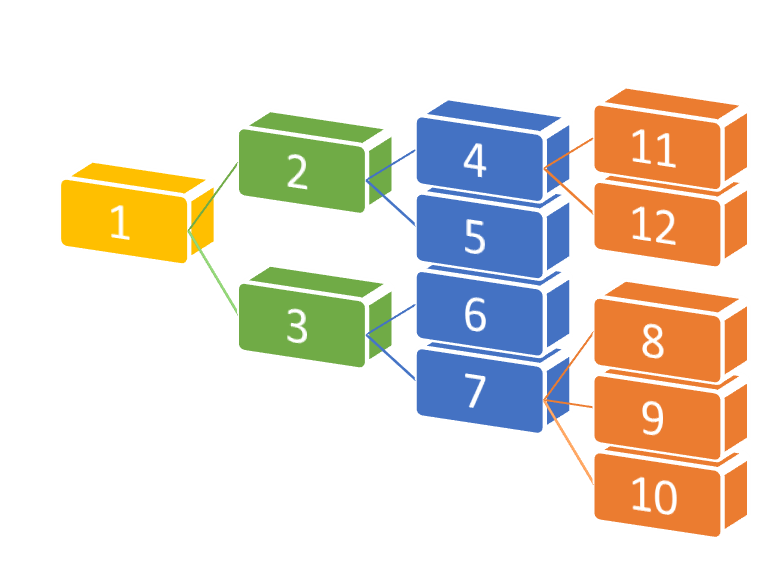
Một dạnh phổ biến của cấu trúc nhánh đó là `Binary Search Tree` (Nhánh nhị phân). Cấu trúc này đặc biệt hiệu quả trong việc truy tìm và truy xuất dữ liệu được lưu trữ. Sự hiệu quả này có được là nhờ ta không cần phải truy toàn bộ dữ liệu trong nhánh, mà chỉ cần truy tại các nhánh liên quan đến phần tử cần tìm. Nhánh nhị phân cần có các đặc điểm sau:
- Các phần tử trong nhánh bên trải cần có giá trị nhỏ hơn phần tử gốc
- Các phần tử trong nhánh bên phải cần có giá trị lớn hơn phần tử gốc
- Các nhánh sau khi chia đều phải có cấu trúc nhánh nhị phân
- Không thể có hai phần tử có dùng giá trị trong nhánh.
Một số ưu, nhược điểm của Tree:
Ưu điểm:
- Phù hợp để lưu trữ dữ liệu phâp cấp rõ rang
- Có thể dễ dạng thêm và xoá các phần tử trong nhánh
- Phần tử chèn vào nhánh nhị phân sẽ được sắp xếp thứ tự ngay lập tức
- Truy xuất dữ liệu hiệu quả với Nhánh nhị phân
Nhược điểm:
- Khó khăn trong việc tái sắp xếp nhánh
- Mỗi phần tử không biết được phần tử gốc phía trên của mình
- Nhánh nhị phân có tốc độ chậm hơn hashtable
- Nhánh nhị phần nếu không được phân nhánh cân bằng, việc truy xuất sẽ không hiệu quả
5. Hashtable / Map
Hashtable (Bảng băm) là một cấu trúc dữ liệu nâng cao và phức tạp, dùng để lưu trữ một lượng lớn dữ liệu và có thể truy xuất dữ liệu một cách nhanh chóng. Hashtable được xây dựng dựa trên khái niệm về cặp `key/value`, trong đó `key` là từ khoá dùng để truy xuất và `value` là giá trị được liên kết với `key`. Hastable thường được ứng dụng trong các cơ sở dữ liệu quy mô lớn.
Trong các Hastable, mỗi khi một cặp `key/value` được thêm vào bảng, `key` sẽ được `hashing` để tạo ra một giá trị số tương ứng, gọi là hash. Việc `hashing` này được thực hiện bằng một hash function. `Hash` sau đó sẽ được sử dụng để tìm `key` của phần tử bất kỳ và truy xuất giá trị của phần tử đó.
Ưu điểm:
- `Key` trong Hashtable có thể ở bất cứ dạng nào, không chỉ là dạng số như trong Array
- Hiệu quả truy xuất dữ liệu rất cao
- Số lượng tác vụ như nhau cho mỗi lần truy xuất
- Sử dụng một lượng tài nguyên như nhau (constant) cho mỗi lần thêm hoặc xoá phần tử
Nhược điểm:
- Ứng dụng sẽ gặp lỗi nếu có hai `key` được chuyển đổi thành cùng một `hash` hoặc có hai `hash` cùng trỏ đến một giá trị



{kind=link}
{kind=link}
{kind=link}
{kind=link}